

Поделиться • 2 июля 2025
Как научить ИИ отличать пластик от металла и почему готовые датасеты — ловушка, которая съест весь бюджет
Как научить ИИ отличать пластик от металла и почему готовые датасеты — ловушка, которая съест весь бюджет


Текст: Рамиль Зайнеев, генеральный директор компании ZeBrains
Фото: Unsplash
Когда мы запустили первую версию ИИ-системы для сортировки мусора, она путала пластиковую бутылку с консервной банкой. Проблема была не в алгоритмах — мы сэкономили на датасетах. Пришлось потратить восемь месяцев и 12 млн руб., чтобы довести точность распознавания до 96%. Вот что мы поняли о настоящей цене машинного обучения кроме того, что экономить не стоит.
Когда мы запустили первую версию ИИ-системы для сортировки мусора, она путала пластиковую бутылку с консервной банкой. Проблема была не в алгоритмах — мы сэкономили на датасетах. Пришлось потратить восемь месяцев и 12 млн руб., чтобы довести точность распознавания до 96%. Вот что мы поняли о настоящей цене машинного обучения кроме того, что экономить не стоит.
Все завязано на обучении перцептронов — базовых ячеек, которые принимают входные данные и возвращают результат: 1 или 0. Представьте черно-белую картинку с одним пикселем. Этот пиксель может быть черным (то есть 0) или белым (то есть 1). Перцептрон, увидев изображение, анализирует пиксель и принимает решение, черный или белый, на основе весового коэффициента (это числовой множитель, который отражает вклад определенного элемента в общий результат. — Прим. ред.), присвоенного каждому цвету.
Собственные данные
В процессе обучения своей системы сортировки отходов Marqus мы использовали многослойную нейронную сеть (так называют ИИ-системы, в которых несколько уровней обработки информации). Каждый слой анализирует данные и передает результат следующему, что позволяет распознавать сложные закономерности. Изначально она не умела определять типы материалов.
Открытых датасетов крайне мало, а те, что есть, либо стоят дорого, либо не покрывают всех требований. Например, найти датасет со всеми типами пластика практически невозможно. Тип материала отхода можно определить на основе различий светоотражающих свойств материалов в разных спектрах, и для этой работы нужен свой собранный датасет.
Без таких специализированных данных эффективность нейросети сведется к нулю. Поэтому мы привлекли специалиста в области пластмасс, который может различить визуально похожие друг на друга виды пластика.
В результате мы подготовили большой датасет — структурированный набор данных для обучения — с изображениями различных материалов и применили подход обратного распространения ошибки: когда нейросеть правильно определяла материал, она получала положительную оценку, а при ошибке — указание на неточность.
Например, если система видела пластиковую бутылку и правильно говорила «это пластик PET», мы подтверждали правильность. Если же она путала PET с пластиком HDPE, мы исправляли ошибку. После множества итераций (сотен тысяч циклов) нейросеть научилась точно определять материалы на новых, ранее не виденных изображениях.






Процесс сбора данных для датасета
Как создавать датасеты
Датасет можно представить в виде большой таблицы, где в одном столбце находятся примеры (фотографии, тексты, звуки), а в другом — правильные ответы к ним.
Вот как выглядит простой пример такой таблицы для распознавания материалов:
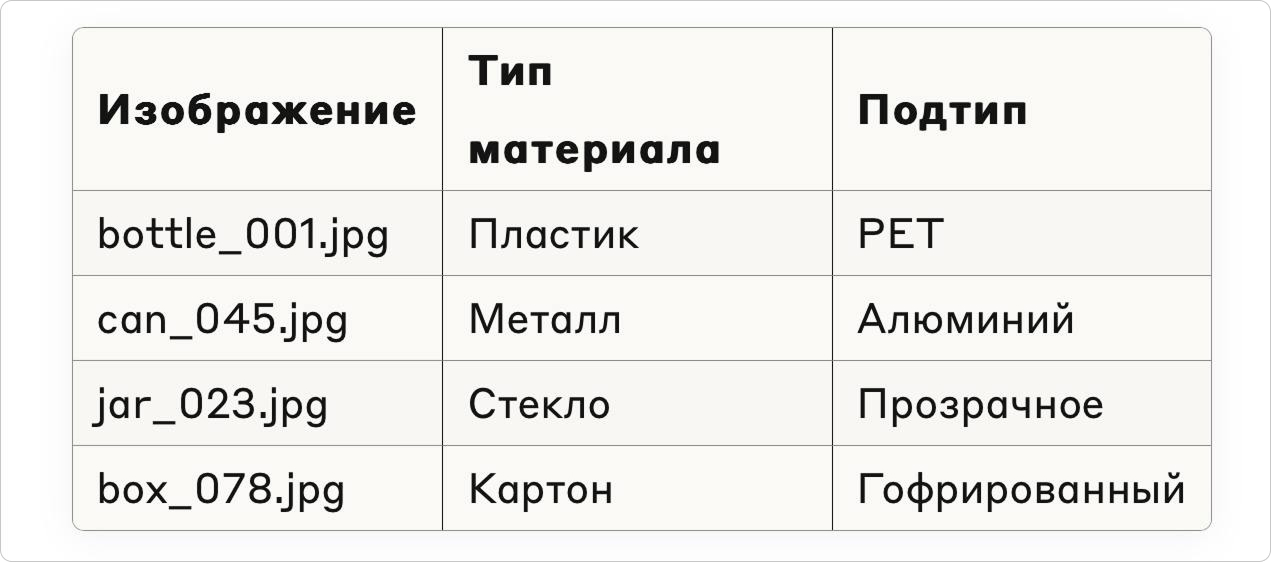
Работа идет по следующем алгоритму:
- собираем большое количество фотографий с объектом, который хотим научить распознавать;
- собираем много фотографий без этого объекта или с другими, чтобы у нейронной сети был пример, что не является нужным объектом;
- далее — выбираем фотографии с комбинациями объектов, чтобы улучшить обучение;
- каждую фотографию подписываем (размечаем), то есть указываем, что на ней изображено.


После обучения тестируем модель на контрольном датасете. Это позволяет убедиться, что она так же правильно работает на новых данных, как и на обучающих.
Процесс пошагово
На схеме, иллюстрирующей процесс внедрения ИИ, показаны две основные петли:
- первая — сбор и обогащение данных с последующим обучением модели;
- вторая — тестирование и оценка качества прогнозов.
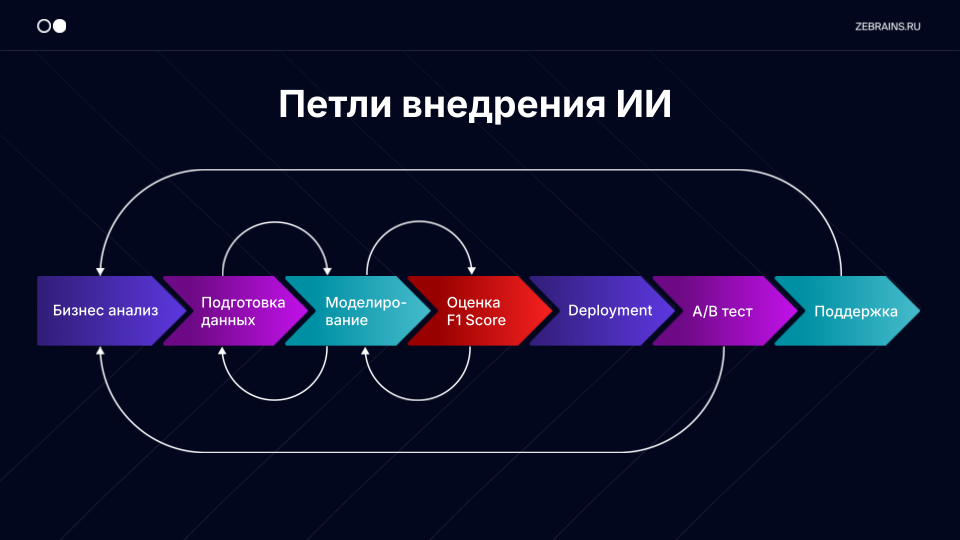
Эти петли интегрированы в более крупный цикл эксплуатации, где новые данные или требования бизнеса инициируют дополнительные итерации.
Вот как это выглядит на практике.
- Первым делом мы проводим аудит и анализ данных: смотрим, что уже есть в наличии и чего не хватает. Если нужных данных нет, нам предстоит либо найти внешние источники, либо наладить их сбор внутри компании.
- После того как данные собраны, вступает в работу техническая команда. Они готовят данные к разметке, очищают их от «шумов» или ненужных фрагментов, которые могут сбивать модель. Например, в случае с видеозаписями мы можем исключить кадры, снятые ночью, чтобы разметчики не тратили на них время.
- Далее создается инструкция для разметчика — очень детальная, чтобы каждый шаг был предельно ясен. В ней мы указываем, что именно разметчик должен делать с данными и какие критерии соблюдать. Разметка может быть ручной, полуавтоматической или полностью автоматизированной, и на каждом этапе ее качество проверяет эксперт.
- После идет этап обогащения и улучшения датасета. Мы добавляем новые параметры, чтобы модель могла распознавать больше характеристик или деталей. Этот этап также включает проверку качества добавленных данных и их корректировку. Обогащение данных позволяет постепенно совершенствовать модель, делая ее более точной и адаптивной.
Данные могут быть изначально цифровые, например тексты в PDF-файлах, и тогда требуется только их разметка. Однако в случае с Marqus нам пришлось сначала оцифровывать реальные объекты (отходы), создавая их цифровые копии путем фотографирования в специальном боксе, а затем размечать эти изображения, присваивая им признаки, например тип материала.
Наш опыт
Для сбора данных мы создали специальный бокс, в котором отходы фотографировали в различных спектральных диапазонах. Например, пластиковую бутылку фотографировали в десяти разных спектрах, затем поворачивали и повторяли процесс. Это позволяло собрать детальные данные о светоотражающих свойствах материалов, необходимых для точной классификации. Всего мы создали около 10 тыс. таких фотографий.
Понимая, что придется собирать данные самостоятельно, мы даже хотели привлечь своих штатных программистов, но этот подход оказался бы слишком дорогим. Программисты, занимаясь разметкой, отвлекались бы от основной работы, а процесс требовал много времени и постоянных проверок. В итоге стало понятно, что лучше привлечь для этого отдельную команду.
Мы даже создали необычную вакансию, «фотограф мусорной хроники», которая привлекла внимание в социальных сетях:
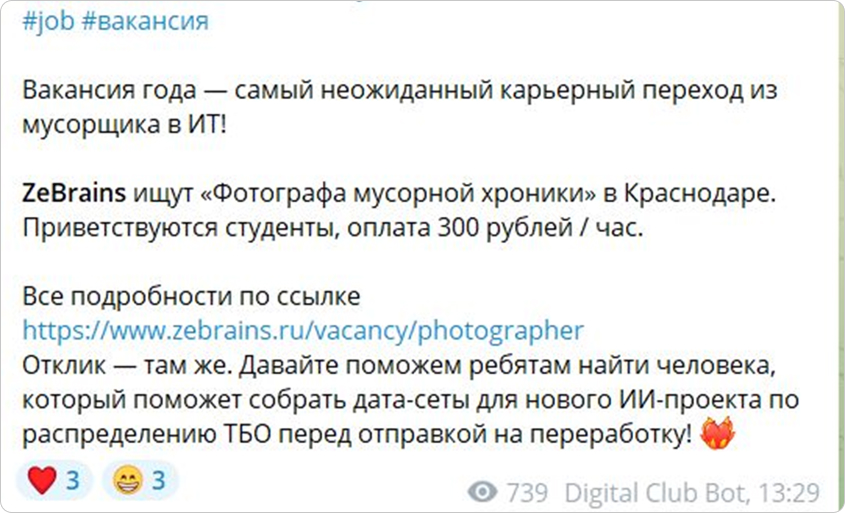
Это помогло найти людей, готовых заниматься специфической, но очень важной для нас работой.
Мы также обратились к волонтерам из Краснодарского края. Работу организовали следующим образом: первая группа волонтеров занималась подготовкой образцов отходов, вторая — фотографировала их и размечала данные, а затем результаты проходили проверку на корректность.
Однако волонтеры быстро устали от монотонной работы. Процесс требовал много внимания и концентрации, так как разметка должна была быть точной и соответствовать строгим критериям. Со временем мотивация у участников снизилась и это сказалось на качестве разметки.
Мы решили эту проблему, разделив задачи на более мелкие и управляемые части, чтобы избежать перегрузки и повысить качество выполнения работы.
После создания начального датасета с фотографиями отходов мы обучали модель для классификации материалов, таких как пластик, металл и стекло. Однако на этапе эксплуатации бизнес решил добавить новый тип отходов, например картон. Это потребовало новых итераций: мы собрали дополнительные данные, обогатили датасет и переобучили модель.
Наш опыт показал, что процесс создания собственного датасета требует значительных ресурсов и времени, но окупается высоким качеством обучения нейронной сети и точностью ее работы. А вот экономия на этапе сбора и разметки данных неизбежно приводит к проблемам в работе системы и дополнительным затратам на ее доработку.




